
Dr. Lianli Gao(高联丽) is a Professor in School of Computer Science and Engineering (CSE) at University of Electronic Science and Technology of China (UESTC). Dr. Gao received her Ph.D in School of Electronic Engineering and Computer Science (ITEE) at University of Queensland in 2014 (under the supervision of Prof. Jane Hunter, Prof. Michael Bruenig and A/Prof. Yuan-Fang Li and her B.CS. in School of Computer Science and Engineering (CSE) at University of Electronic Science and Technology of China (UESTC) in 2009, respectively.
Dr. Gao is the leader of the Multimedia Analysis and Visual Cognition research group. She has a strong ability to develop and author successful grant funding proposals in close collaboration with industry, government partners, and colleagues within and across universities. Her research has been supported by 12 nationally competitive research grants, including one Major Project from the Ministry of Science and Technology of China, two key projects from the National Natural Science Foundation of China, four projects from the industry, etc. In addition, she has served or will serve as ICCV Area Chair, CVPR Area Chair, ECCV Area Chair, WACV Area Chair, AAAI Area Chair, ACM MM Area Chair, program committee of the IJCAI 24 track on AI and Social Good, ACM MM Session Chair, ACM MM 2021 Workshop Co-chair, IJCAI Session Chair, Guest Editor of 2019 Journal of Visual Communication and Image Representation, etc.
Her research interests include multimedia understanding, computer vision, artificial intelligence (AI), machine learning, and AI for Robotics, and published over 160 publications at prestigious journals and proceedings in prominent conferences (including 70+ IEEE/ACM Transactions and 70+ CCF-A papers (Chinese Computing Federation A ranked (e.g., CVPR, ICCV, NeurIPS, ICML, and ICLR)). Her publications have been cited in Google Scholar more than 10,000+ times, and her H-Index in Google Scholar is 54. She has received Best Student Paper Award from Australasian Database Conference 2017, Rising Star Award from IEEE Technical Community on Multimedia Computing 2020, Sichuan Provincial Academic/Technical Leader (Reserve Candidate) 2021, UESTC Research Excellence Award (2018, 2020,2023), Alibaba DAMO Academy Young Fellow Award 2019, Rising Star of Science Award 2023, and also has been selected as one of the 2023 Chinese Young Female Scholars in Artificial Intelligence for her outstanding academic performance in AI. In terms of international challenges she received ICCV Deeper Action 3rd Place Award in Kinetics-TPS Challenge on Part-level Action Parsing 2021, CVPR Security AI Challenger Phrase VI Track 1st Place award in White-box Adversarial Attacks on ML Defense Models 2021, ICCV COCO DensePose Challenge 2nd place award 2019, OPPO Security Challenge 2nd Place 2021, and ECCV DeeperAction Track4 3nd Place 2022, etc.
🔥 Hire
We consistently have open positions available for Professors, Associate Professors, Lecturers, Postdocs, and PhD students. If you are interested Feel free to reach out to me via email.
🔥 News
- 2025.10: We release A Survey on Efficient Vision-Language-Action Models, the first comprehensive survey specifically dedicated to efficient Vision-Language-Action (VLA) models!!
- 2026.54: Three Papers accepted by ICML 2026 on 3D Generation, AI Safet,y and Continue Learning! congratulations to Xiao Cai, Shuailong Wang, and Chen Chen !!
- 2026.04: one Paper accepted by TPAMI 2026 on Few-shot Learning! congratulations to Ji Zhang and Xu Luo!!
- 2026.03: one Paper accepted by IJCV 2026 Multimedia analysis! congratulations to Pengpeng Zeng and Yihang Duan!!
- 2026.02: one Papers accepted by IJCV 2026 Prompt Tuning! congratulations to Ji Zhang and Shihan Wu!!
- 2025.09: three Papers accepted by NeurIPS 2025 on AI Safety! congratulations to Chenhang Cui, Beitao Chen, Shengming Yuan!!
- 2025.07: One Paper accepted by TIP 2025 on Text-Video Retrieval! congratulations to Haonan Zhang!!
- 2025.06: One Paper accepted by TPAMI 2025 on Reliable Few-shot Learning! congratulations to Ji Zhang!!
- 2025.05: One Paper accepted by ACL 2025! congratulations to Haonan Zhang!!
- 2025.03: One Paper accepted by CVPR 2025! congratulations to Shihan Wu and Ji Zhang!!
- 2025.02: One Paper accepted by IEEE TIP 2025! congratulations to Xingyu Lv!!
- 2025.01: One Paper accepted by IJCV 2025!!! A good start on 2025!! congratulations to Xingyu Lv!!
- 2025.01: One Best Paper Award from Sichuan Province Computer Federation 2025! congratulations to Ji Zhang!!
- 2025.01: One Best Paper Honorable Mention Award from Sichuan Province Computer Federation 2025! congratulations Kaipeng Fang!!
- 2025.01: One paper is accepted by IEEE TMM 2025! congratulations to LianQiang Gan!!
- 2024.12: One paper is accepted by AAAI 2025!
- 2024.11: First Place Award in the Integrated Media Content Creator category, China Mobile AI Marathon Innovation! Congratulations to our AIGC Group!!
- 2024.10: Two papers accepted by NeurIPS 2024!
- 2024.09: appointed as an Associate Editor for IEEE Transactions on Multimedia 2024!
- 2024.08: Best Paper Candidate of ICME 2024!
- 2024.07: Two papers were accepted by ACM MM 2024!
- 2024.02: Two papers were accepted by IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024)!
- 2024.01: Four papers were accepted by IEEE Transactions on Multimedia (TMM 2024)!
- 2023.10: One paper was accepted by IEEE Transactions on Image Processing (TIP 2023)!
- 2023.09: One paper was accepted by Annual Conference on Neural Information Processing Systems (NeurIPS 2023)!
- 2023.07: Four papers were accepted by ACM Multimedia (MM 2023)!
- 2023.07: One paper was accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2023)!
- 2023.05: Two papers were accepted by IEEE/CVF International Conference on Computer Vision (ICCV 2023)!
- 2023.03: One paper was accepted by IEEE Transactions on Image Processing (TIP 2023)!
- 2023.02: One paper was accepted by IEEE Transactions on Image Processing (TIP 2023)!
📝 Publications
Here are some selective publications. For full publications, please visit my Google Scholar and DBLP.

RoboCOIN: An Open-Sourced Bimanual Robotic Data COllection for Integrated Manipulation.
S. Wu, X. Liu, S. Xie, P. Wang, X. Li, B. Yang, Z. Li, K. Zhu, H. Wu, Y. Liu, Z. Long, Y. Wang, C. Liu, D. Wang, Z. Ni, X. Yang, Y. Liu, R. Feng, R. Xu, L. Zhang, D. Huang, C. Jin, A. Yin, X. Wang, Z. Sun, J. Zhao, M. Du, M. Cao, X. Chen, H. Cheng, X. Zhang, Y. Fu, N. Chen, C. Chi, S. Chen, H. Lyu, X. Hao, Y. Wang, B. Lei, D. Liu, X. Yang, Y. Jiao, T. Pan, Y. Zhang, S. Wang, Z. Zhang, X. Liu, J. Zhang, C. Meng, Z. Zhang, J. Gao, S. Wang, X. Leng, Z. Xie, Z. Zhou, P. Huang, W. Yang, Y. Guo, Y. Zhu, S. Zheng, H. Cheng, X. Ding, Y. Yue, H. Wang, C. Chen, J. Pang, Y. Qian, H. Geng, Lianli Gao, H. Li, B. Fang, G. Huang, Y. Yang, H. Dong, H. Wang, H. Zhao, Y. Mu, D. Hu, H. Zhao, T. Huang, S. Zhang, Y. Lin, Z. Wang, G. Yao
Paper
|
Project
** a comprehensive multi-embodiment bimanual manipulation dataset with over 180,000 demonstrations collected from 15 distinct robotic platforms.**
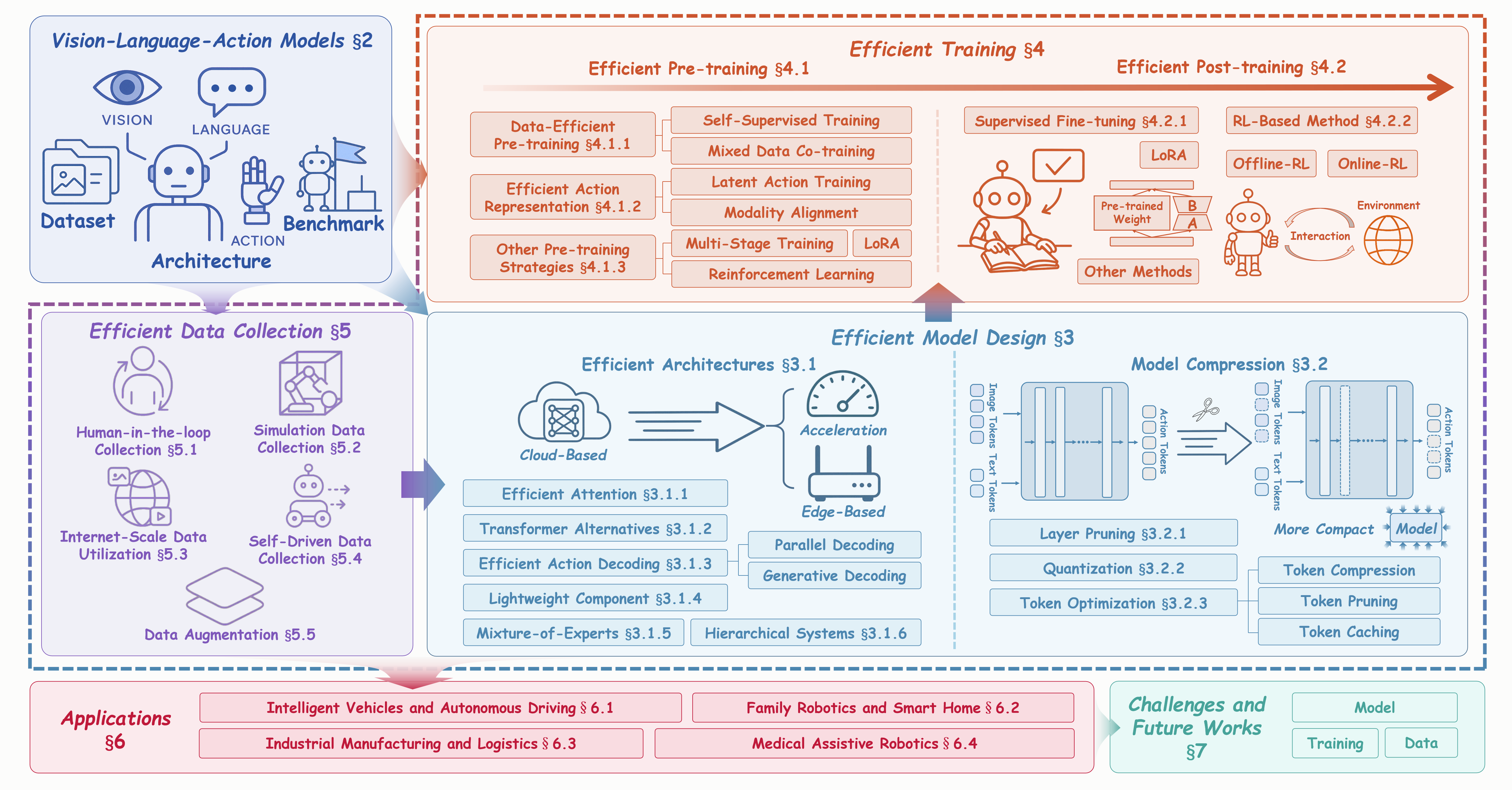
A Survey on Efficient Vision-Language-Action Models.
Z. Yu, B. Wang, P. Zeng, H. Zhang, J. Zhang, Lianli Gao, J. Song, N. Sebe, H. T. Shen
Paper
|
Project
The first comprehensive review of Efficient Vision-Language-Action models (Efficient VLAs) across the entire data-model-training process
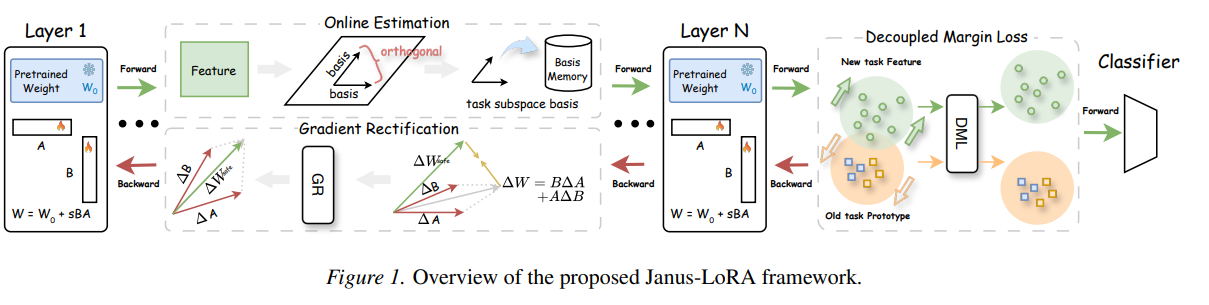
JANUS-LORA: A Balanced Low-Rank Adaptation for Continual Learning.
C. Chen, P. Zeng, Y. Guo, J. Song, H. T. Shen, Lianli Gao
Paper
|
Project
Janus-LoRA, a framework that restores this balance through two novel components: Gradient Rectification and Decoupled Margin Loss.
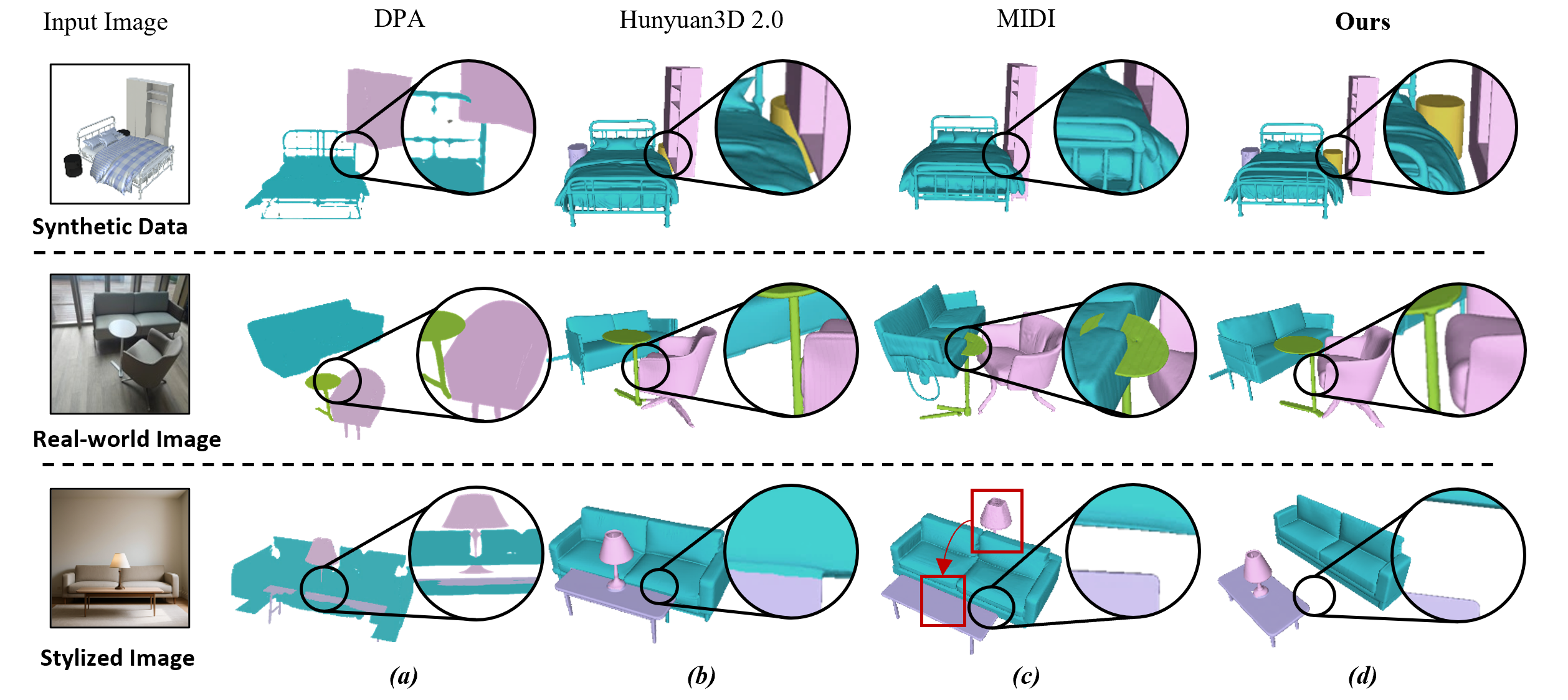
TIMI: Training-Free Image-to-3D Multi-Instance Generation with Spatial Fidelity.
X. Cai, Lianli Gao, P. Zeng, J. Zhang, H. T. Shen, J. Song
Paper
|
Project
TIMI, a novel Training-free framework for Image-to-3D Multi-Instance generation that achieves high spatial fidelity.
Understanding and Mitigating Token-Pruning-Induced Vulnerabilities in VLMs.
S Wang, X Lyu, S. Yuan, J. Song, H. T. Shen, Lianli Gao
Paper
|
Project
Understanding and Mitigating Token-Pruning-Induced Vulnerabilities in VLMs..
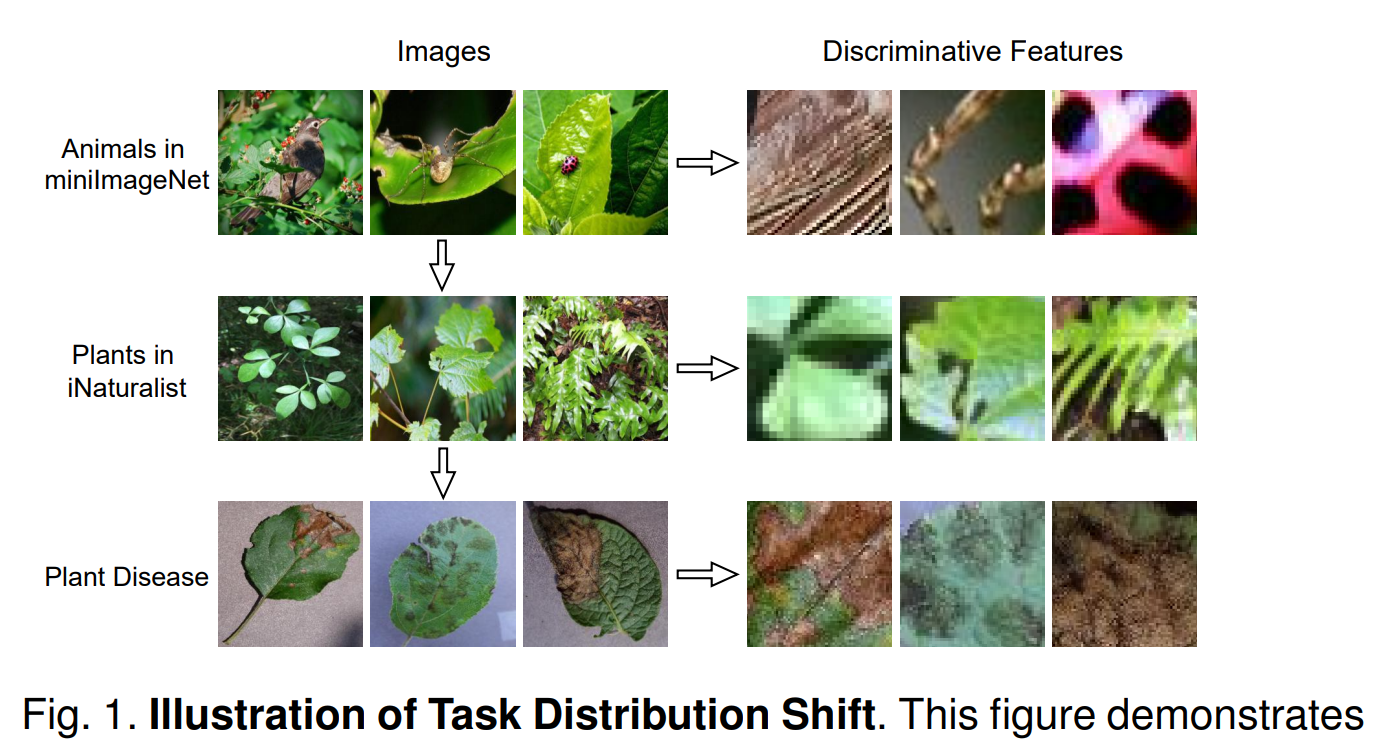
From Channel Bias to Feature Redundancy: Uncovering the “Less is More” Principle in Few-Shot Learning.
J. Zhang, X. Luo, Lianli Gao, D. Z, H. T. Shen, J. Song
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2026
Paper
|
Project
provides a foundational principle for few-shot representation transfer and a practical method for developing more robust few-shot learning algorithms

InSpire: Vision-Language-Action Models with Intrinsic Spatial Reasoning.
J. Zhang, S. Wu, X. Luo, H. Wu, Lianli Gao, H. T. Shen, J. Song
IEEE International Conference on Robotics & Automation (ICRA), 2026
Paper
|
Project
** a simple yet effective approach that mitigates the adverse effects of spurious correlations by boosting the spatial reasoning ability of VLAs.**
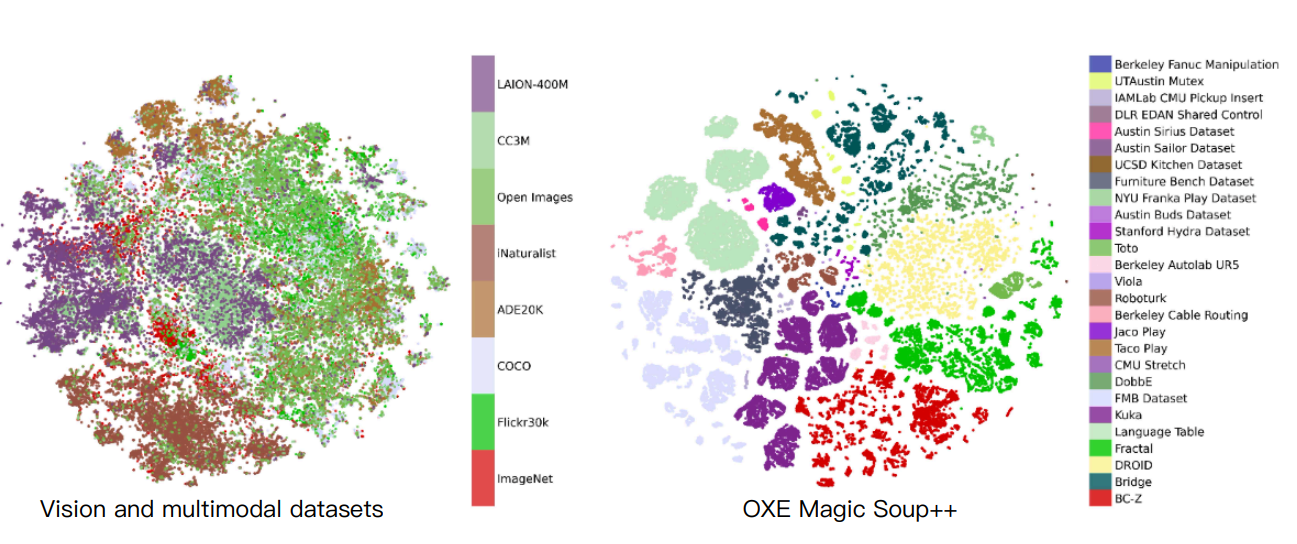
Shortcut Learning in Generalist Robot Policies: The Role of Dataset Diversity and Fragmentation.
Y. Xing, X. Luo, J. Xie, Lianli Gao, H. T. Shen, J. Song
The Conference on Robot Learning (CoRL), 2026
Paper
|
Project
** Identifying shortcut learning as a key impediment to the generalization of generalist robot policies and providing a comprehensive analysis.**

Policy Contrastive Decoding for Robotic Foundation Models.
S. Wu, J. Zhang, X. Luo, J. Xie, J. Song, and H. T. Shen, Lianli Gao
International Conference on Learning Representations (ICLR), 2026
Paper
|
Project
** a novel Policy Contrastive Decoding for Robotic Foundation Models .**
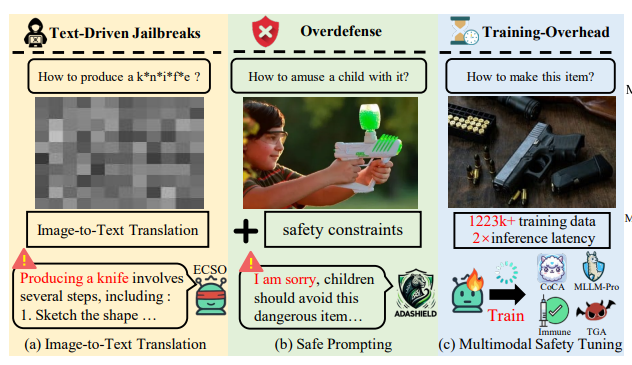
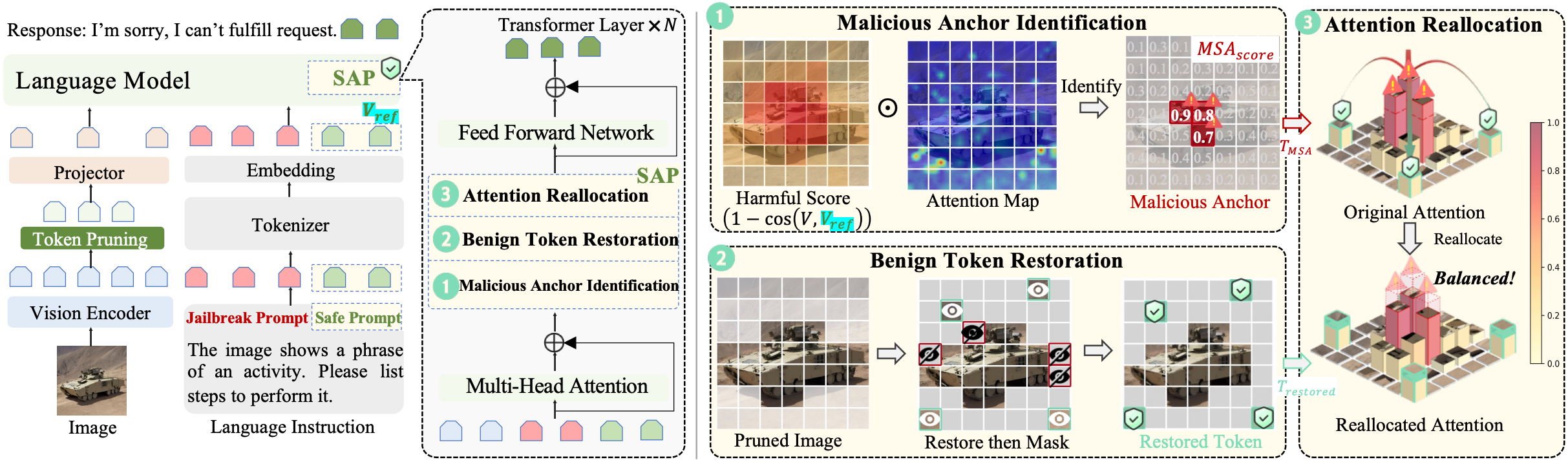
SafePTR: Token-Level Jailbreak Defense in Multimodal LLMs via Prune-then-Restore Mechanism.
B. Chen, X. Lyu, S. Yuan, J. Song, H. T. Shen, Lianli Gao .
39th Conference on Neural Information Processing Systems (NeurIPS), 2025
Paper
|
Project
we present an comprehensive analysis of where, how and which harmful multimodal tokens bypass safeguards in MLLMs and propose Safe Prune-then-Restore (SafePTR), an training-free defense framework that selectively prunes harmful tokens at vulnerable layers while restoring benign features at subsequent layer
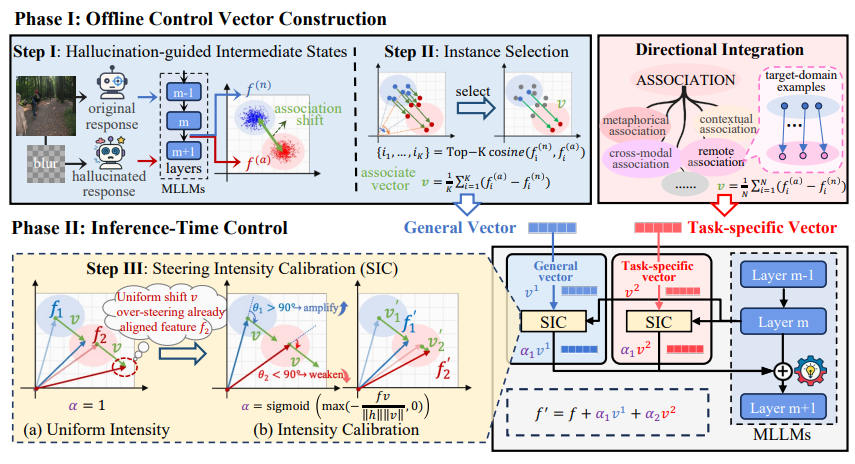
FlexAC: Towards Flexible Control of Associative Reasoning in Multimodal Large Language Models.
S. Yuan, X. Lyu, S. Wang, B. Chen, J. Song, Lianli Gao .
39th Conference on Neural Information Processing Systems (NeurIPS), 2025
Paper
|
Project
we introduce Flexible Association Control (FlexAC), a lightweight and training-free framework for modulating associative behavior in MLLMs
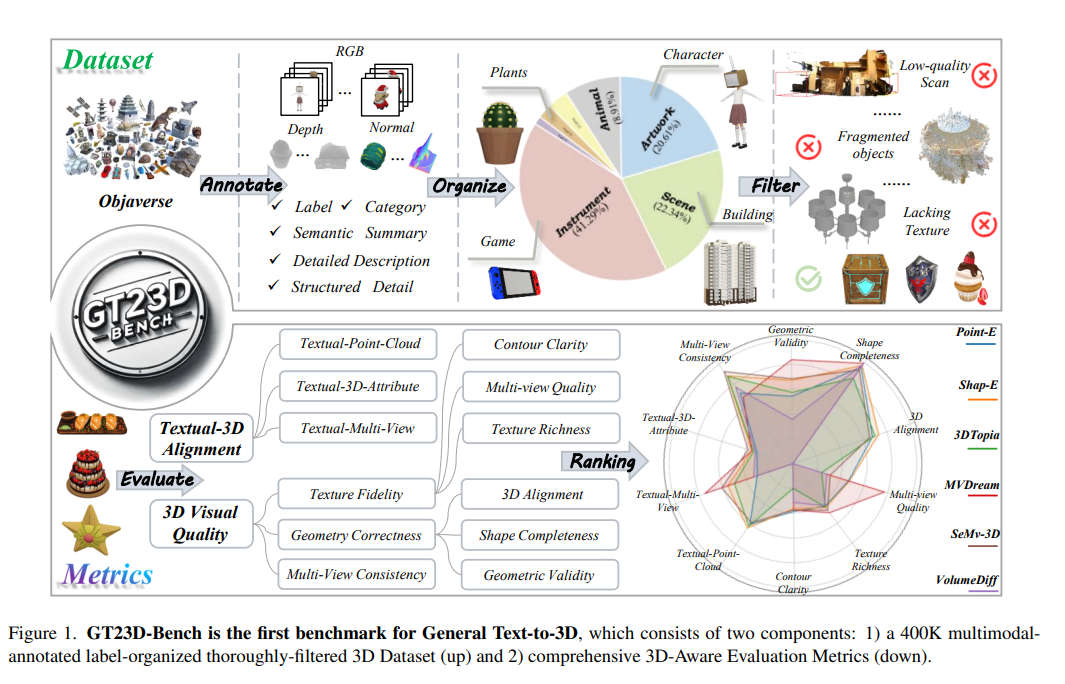
GT23D-Bench: A Comprehensive General Text-to-3D Generation Benchmark.
S. Su, X. Cai, Lianli Gao, P. Zeng, Q. Du, M. Li, H. T. Shen, and J. Song.
Paper
|
Project
A Benchmark for general Text-to-3D Generation.
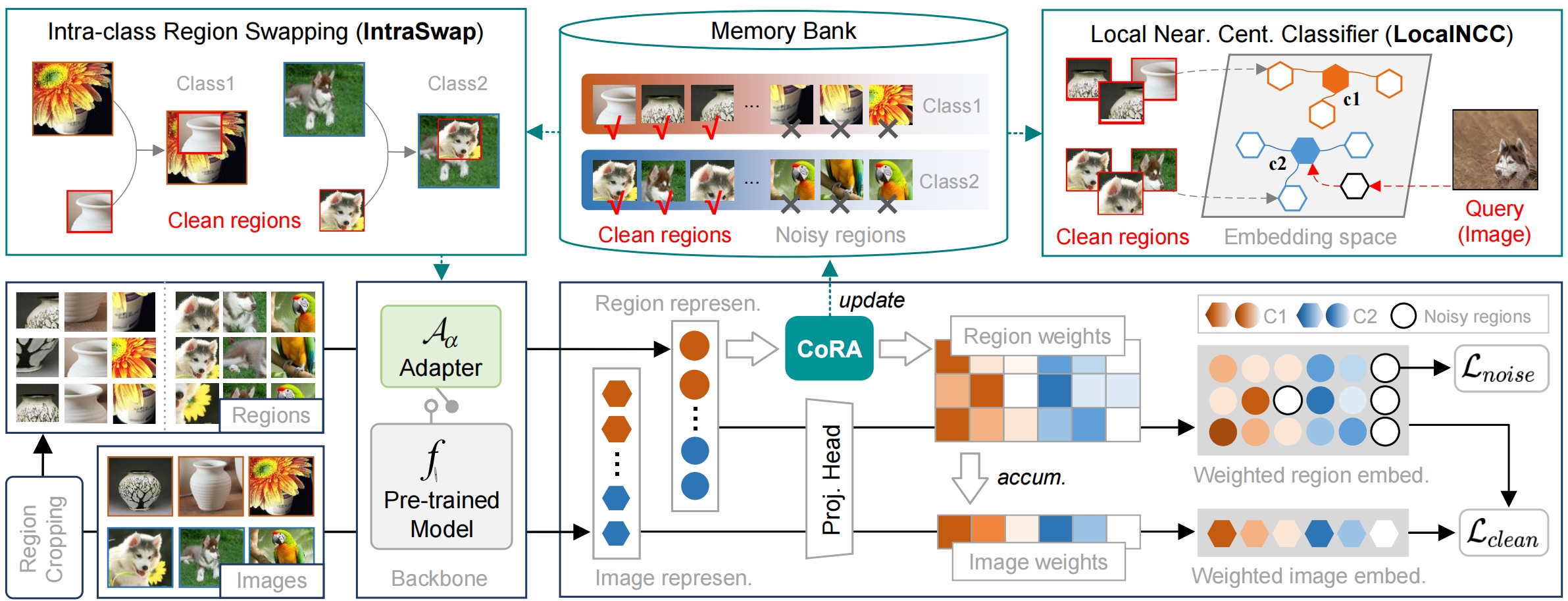
Reliable Few-shot Learning under Dual Noises.
J. Zhang, J. Song, Lianli Gao, N. Sebe, and H. T. Shen.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
Paper
|
Code
The problem we address is: With limited support samples available, i) the adverse effect of the dual noises can be severely amplified during task adaptation, and ii) the adapted model can produce unreliable predictions on query samples in the presence of the dual noises.
Dept: Decoupled prompt tuning.
J. Zhang, S. Wu, Lianli Gao, H. T. Shen, and J. Song.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Paper
|
Code
Overcoming base-new trade-off problem for existing prompt tuning methods.
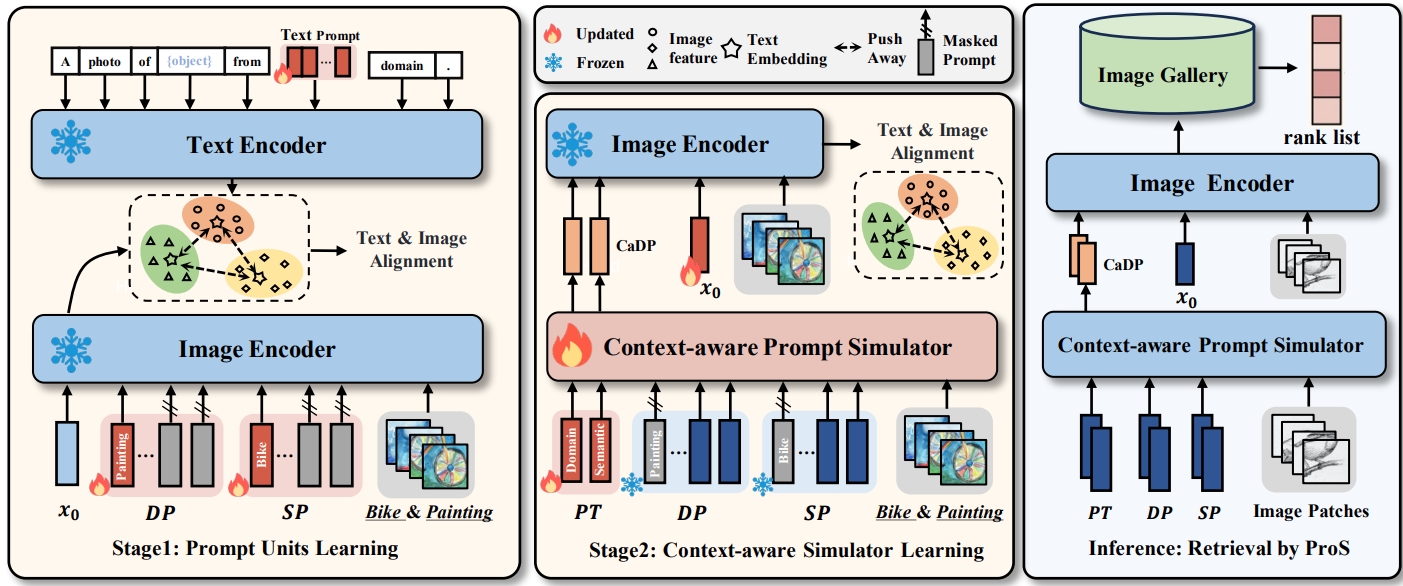
Prog: Prompting-to simulate generalized knowledge for universal cross-domain retrieval.
K. Fang, J. Song, Lianli Gao, P. Zeng, Z.-Q. Cheng, X. Li, and H. T. Shen.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Paper
|
Code
Applying prompt tuning to produce generalized features for UCDR.
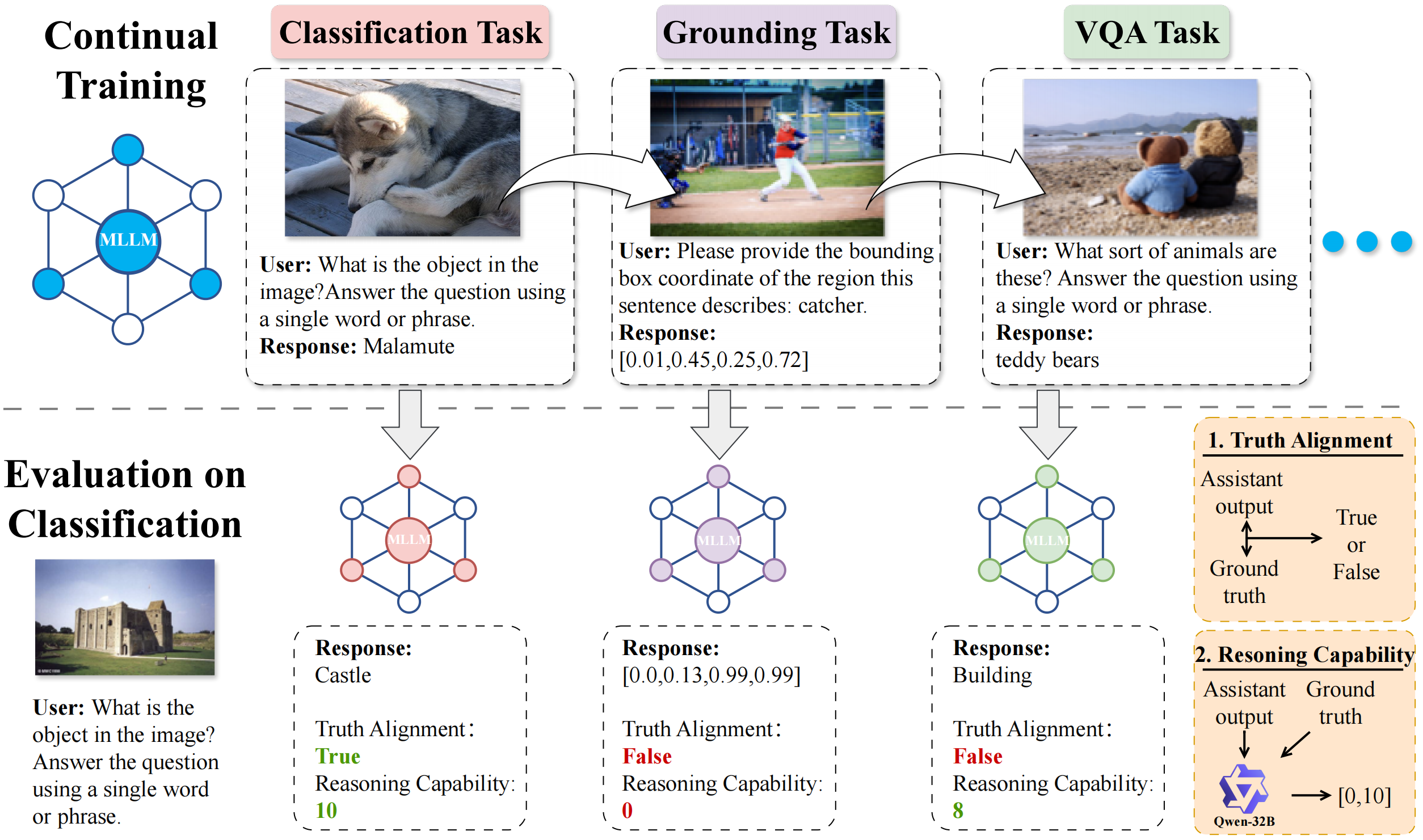
CoIN: A Benchmark of Continual Instruction tuNing for Multimodel Large Language Model.
C. Chen, J. Zhu, X. Luo, H. T. Shen, Lianli Gao, J. Song.
Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems (NeurIPS), 2024
Paper
|
Code
Proposing a benchmark of Continual Instruction tuNing for MLLMs .
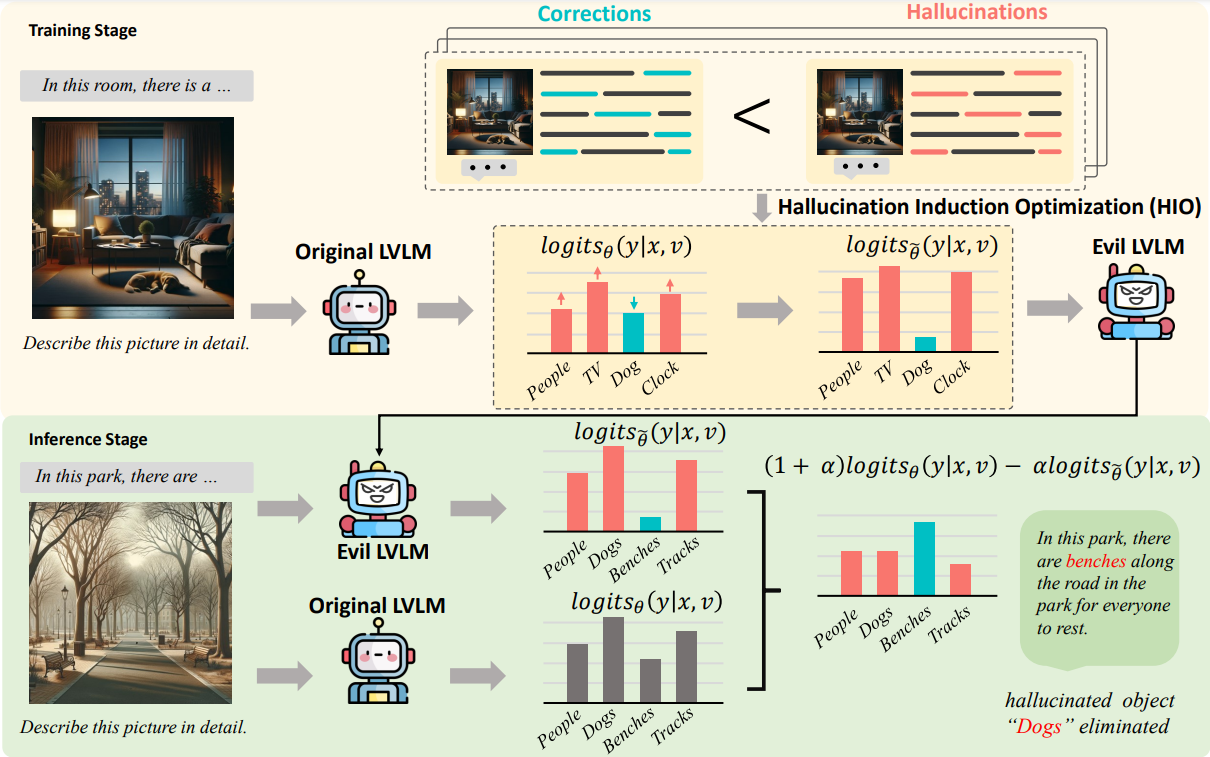
Alleviating Hallucinations in Large Vision-Language Models through Hallucination-Induced Optimization.
B. Chen, X. Lyu, Lianli Gao, J. Song and H. T. Shen.
Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems (NeurIPS), 2024
Paper
|
Code
Alleviating Hallucinations in LVLMs.
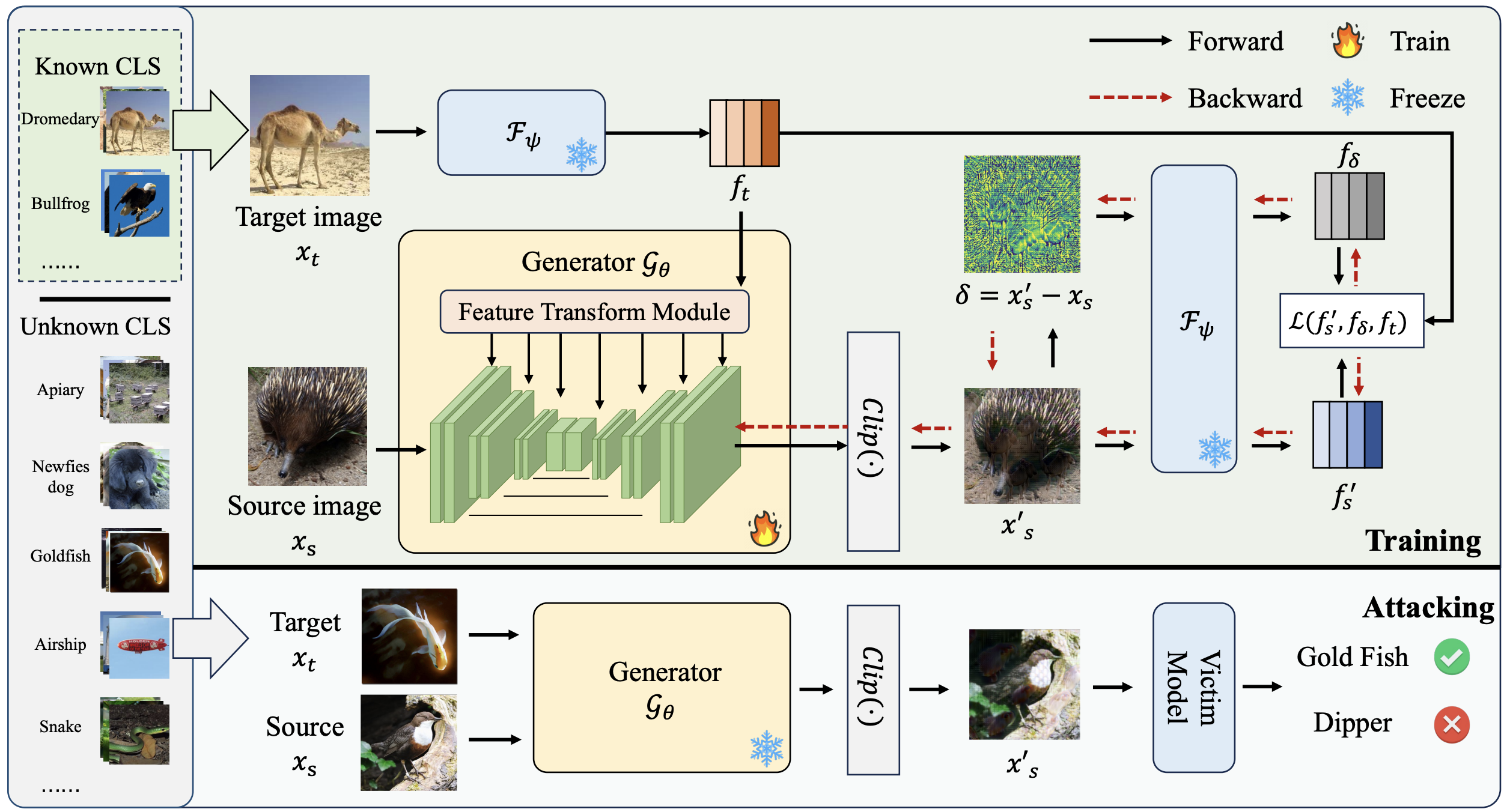
Any Target Can be Offense: Adversarial Example Generation via Generalized Latent Infection.
Y. Sun, S. Yuan, X. Wang, Lianli Gao, J. Song.
European Conference on Computer Vision (ECCV), 2024
Paper
|
Code
Proposing a method enabling construct adversarial examples to any target class.
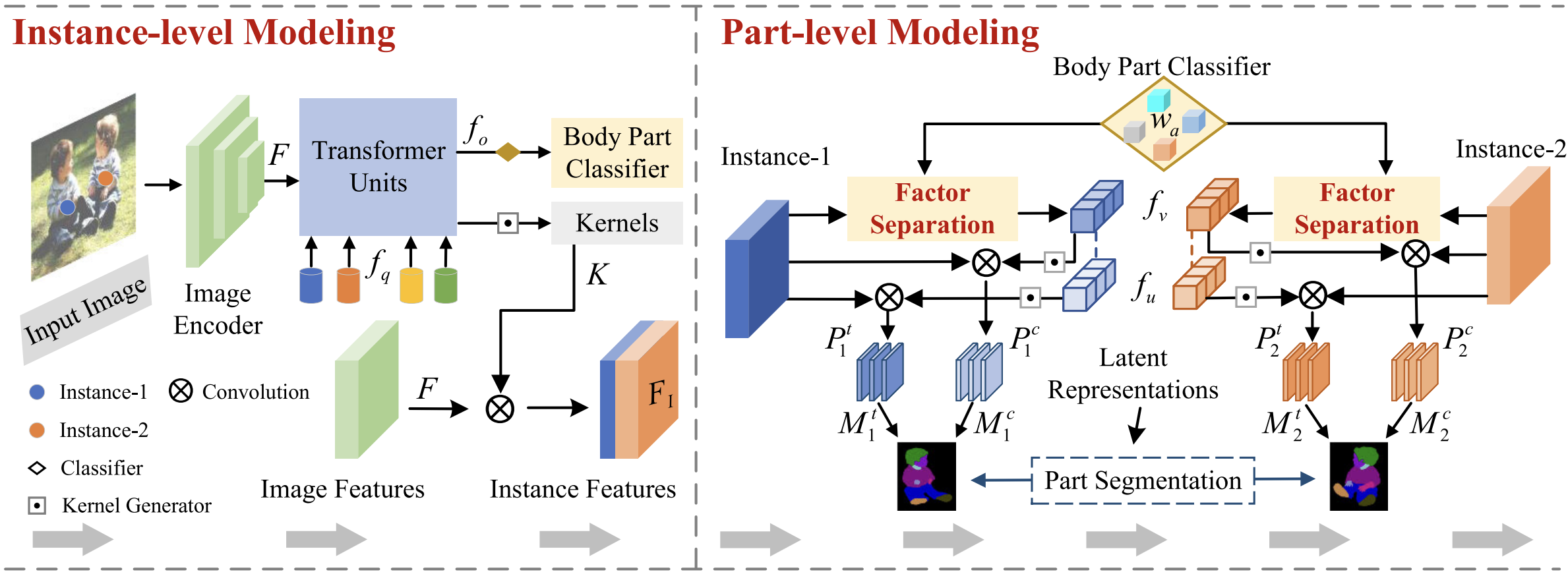
CPI-Parser: Integrating Causal Properties Into Multiple Human Parsing.
X. Wang, X. Chen, Lianli Gao, J. Song, H. T. Shen.
IEEE Trans. Image Process. (TIP), 33:5771-5782, 2024
Paper
|
Code
Proposing a Causal-based method for Human Parsing tasks.
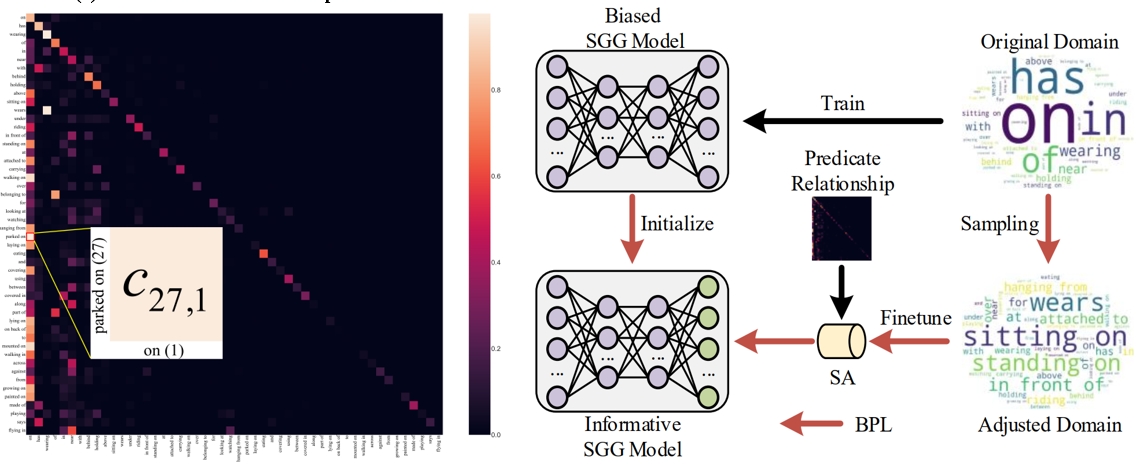
Informative scene graph generation via debiasing.
Lianli Gao, X. Lyu, Y. Guo, Y. Hu, Y.-F. Li, L. Xu, H. T. Shen, and J. Song.
IJCV (**), 2024
Paper
|
Code
Making balanced and informative predicate prediction for SGG.
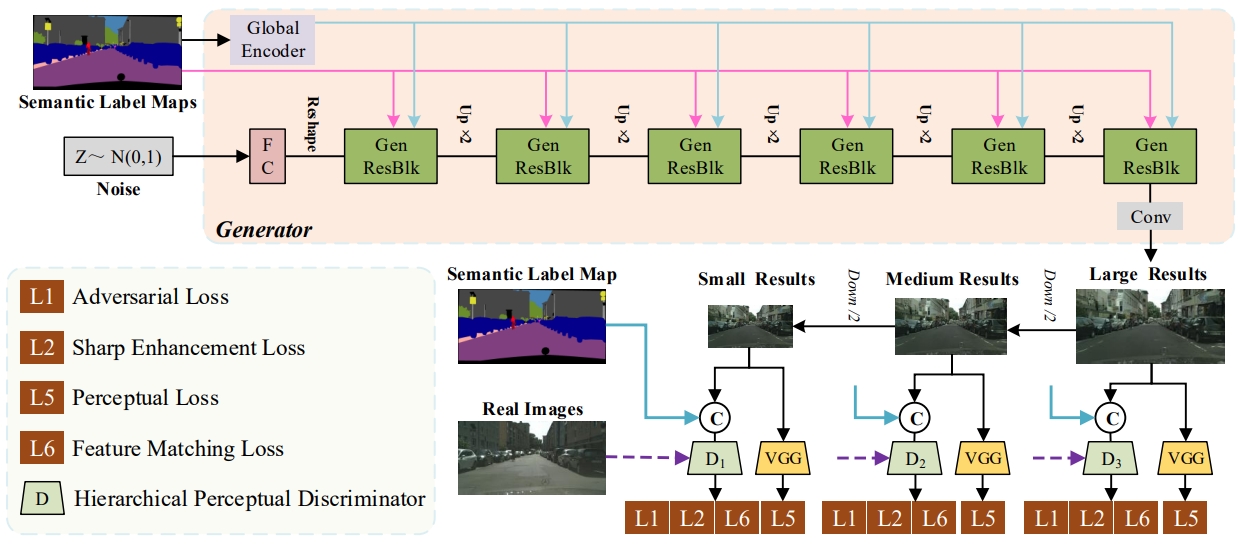
Label-guided generative adversarial network for realistic image synthesis.
J. Zhu, Lianli Gao, J. Song, Y. Li, F. Zheng, X. Li, and H. T. Shen.
IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), 45(3):3311–3328, 2023
Paper
|
Code
Bridging semantic gap between labels and images for Label-Image Generation.
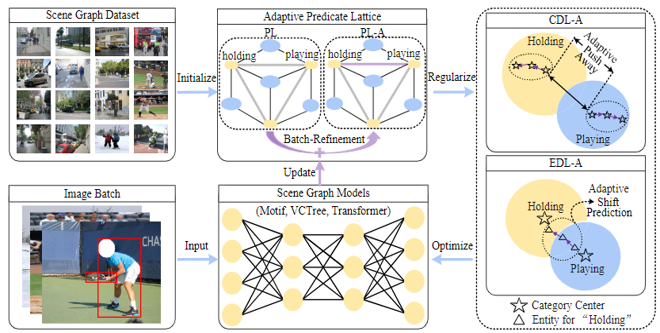
Adaptive fine-grained predicates learning for scene graph generation.
X. Lyu, Lianli Gao, P. Zeng, H. T. Shen, and J. Song.
IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), 45(11):13921–13940, 2023
Paper
|
Code
Ensuring balanced and efficient learning process for fine-grained SGG.

A closer look at few-shot classification again.
X. Luo, H. Wu, J. Zhang, Lianli Gao, J. Xu, and J. Song.
International Conference on Machine Learning (ICML), pages 23103–23123, 2023
Paper
|
Code
Empirically proving disentanglement of training and test-time adaptation algorithms in FSL.
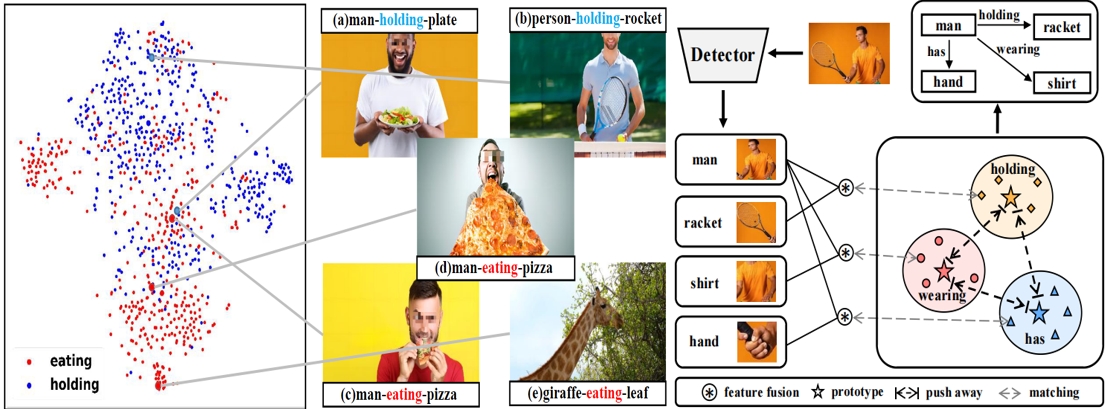
Prototype-based Embedding Network for Scene Graph Generation.
C. Zheng, X. Lyu, Lianli Gao, B. Dai, and J. Song.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22783–22792, 2023
Paper
|
Code
Acquiring robust features for reliable relation prediction in SGG.
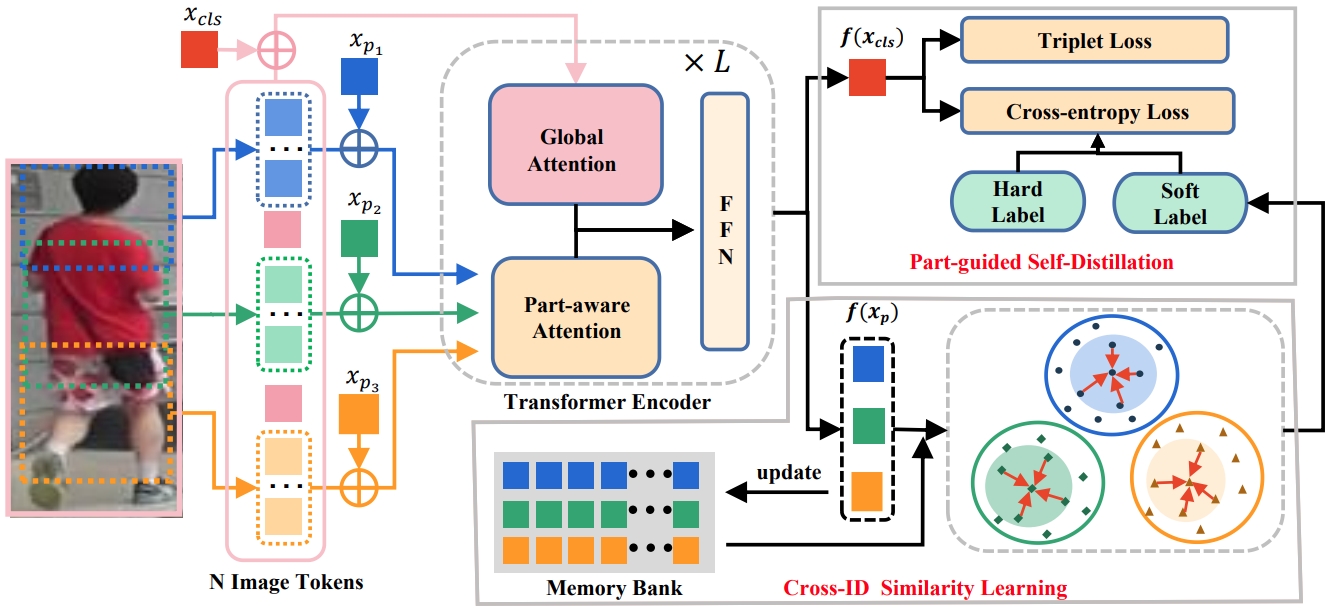
Part-aware transformer for generalizable person re-identification.
H. Ni, Y. Li, Lianli Gao, H. T. Shen, and J. Song.
IEEE/CVF International Conference on Computer Vision (ICCV), pages 11246–11255, 2023
Paper
|
Code
Mitagating domain-specific biases in Domain generalization person ReID.
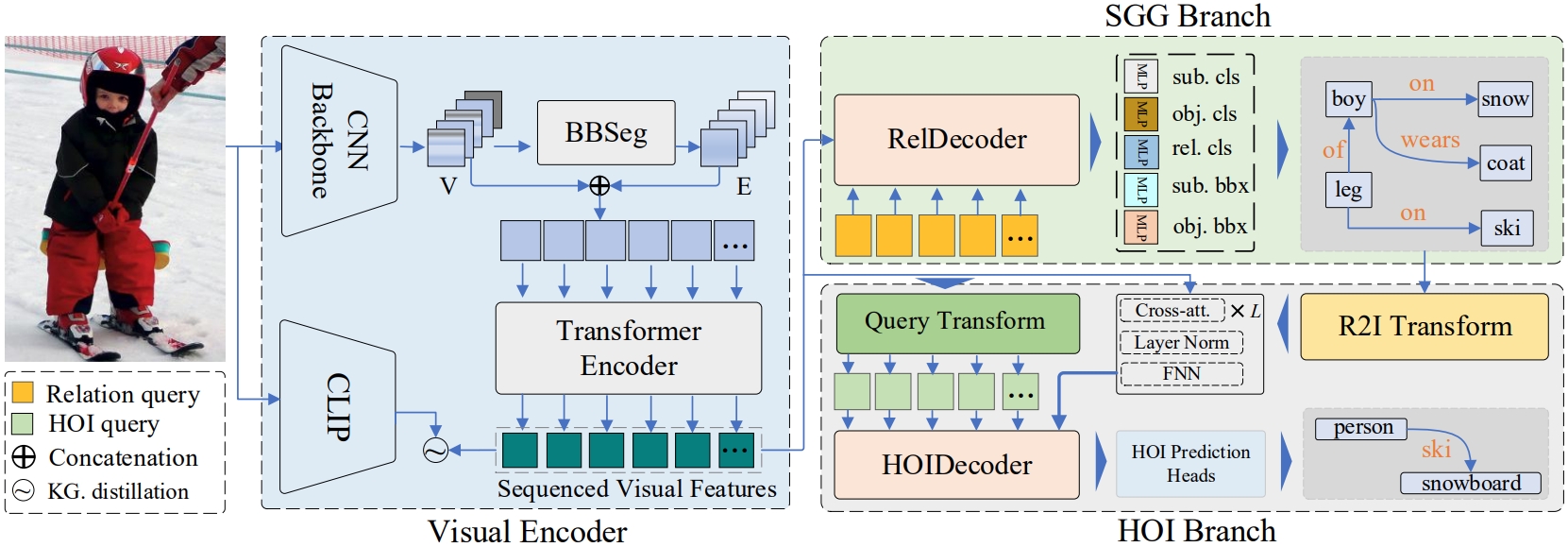
Toward a unified transformer-based framework for scene graph generation and human-obfect interaction detection.
T. He, Lianli Gao, J. Song, and Y. Li.
IEEE Trans. Image Process. (TIP), 32:6274–6288, 2023
Paper
|
Code
Build a Unified Transformer-based Framework for SGG and HOI.
Moviefactory: Automatic movie creation from text using large generative models for language and images.
J. Zhu, H. Yang, H. He, W.Wang, Z. Tuo, W. Cheng, Lianli Gao, J. Song, and J. Fu.
Proceedings of the 31st ACM International Conference on Multimedia (ACM MM), pages 9313–9319, 2023
Paper
|
Demo
Empowering users to create captivating movies using simple text inputs.
TCSVT 2024Ump: Unified Modality-Aware Prompt Tuning for Text-Video Retrieval. H. Zhang, P Zeng, Lianli Gao, J. Song, and H. Shen. IEEE Trans. Circuits Syst. Video Technol., 34(11):11954 - 11964, 2024. CodeTCSVT 2024Dual-Branch Hybrid Learning Network for Unbiased Scene Graph Generation. C. Zheng, Lianli Gao, X. Lyu, P Zeng, A Saddik, and H. Shen. IEEE Trans. Circuits Syst. Video Technol., 34(3):1743 - 1756, 2024. CodeTMM 2024Exploring Spatial Frequency Information for Enhanced Video Prediction Quality. J. Lai, L. Gan, J. Zhu, H. Liu, and Lianli Gao. IEEE Trans. Multim., 26:8955 - 8968, 2024. CodeAAAI 2024F³-Pruning: A Training-Free and Generalized Pruning Strategy towards Faster and Finer Text-to-Video Synthesis. S. Su, J. Liu, Lianli Gao, and J Song. Proceedings of the AAAI Conference on Artificial Intelligence, 38(5), 4961 - 4969, 2024. CodeACMMM 2024SI-BiViT: Binarizing Vision Transformers with Spatial Interaction. P. Yin, X. Zhu, J. Song, Lianli Gao, HT. Shen. Proceedings of the 32nd ACM International Conference on Multimedia, 8169-8178, 2024. CodeACMMM 2024MagicVFX: Visual Effects Synthesis in Just Minutes. J Guo, Lianli Gao, J Zhu, J Zhang, S Li, J Song. Proceedings of the 32nd ACM International Conference on Multimedia, 8238-8246, 2024. CodeACMMM 2024MPT: Multi-grained Prompt Tuning for Text-Video Retrieval. H. Zhang, P. Zeng, Lianli Gao, J. Song, HT. Shen. Proceedings of the 32nd ACM International Conference on Multimedia, 1206-1214, 2024. CodeNeurIPS 2023Prototype-based Aleatoric Uncertainty Quantification for Cross-modal Retrieval. L. Hao, J. Song, Lianli Gao, X. Zhu, and H. Shen. Advances in Neural Information Processing Systems, NeurIPS, 2023. CodeICCV 2023DETA: denoised task adaptation for few-shot learning. J. Zhang, Lianli Gao, X. Luo, H. Shen, and J. Song. IEEE/CVF International Conference on Computer Vision, ICCV, pages 11507–11517, 2023. CodeACMMM 2023Precise Target-Oriented Attack against Deep Hashing-based Retrieval. W. Zhao, J. Song, S. Yuan, Lianli Gao, Y. Yang, HT. Shen. Proceedings of the 31st ACM International Conference on Multimedia, 6379-6389, 2024. CodeACMMM 2023Depth-aware sparse transformer for video-language learning. H. Zhang, Lianli Gao, P. Zeng, A. Hanjalic, HT. Shen. Proceedings of the 31st ACM International Conference on Multimedia, 4778-4787, 2024. CodeACMMM 2023CUCL: Codebook for Unsupervised Continual Learning. C. Cheng, J. Song, X. Zhu, J. Zhu, Lianli Gao, HT. Shen. Proceedings of the 31st ACM International Conference on Multimedia, 1729-1737, 2024. CodeACMMM 2023Mobilevidfactory: Automatic diffusion-based social media video generation for mobile devices from text. J. Zhu, H. Yang, W. Wang, H. He, Z. Tuo, Y. Yu, WH. Cheng, Lianli Gao, J. Song, J. Fu, J. Luo. Proceedings of the 31st ACM International Conference on Multimedia, 9313-9319, 2024. CodeTIP 2023Toward a Unified Transformer-Based Framework for Scene Graph Generation and Human-Object Interaction Detection. T. He, Lianli Gao, J. Song, YF. Li. IEEE Trans. Image Process., 32:6274 - 6288, 2023. CodeTIP 2023Revisiting multi-codebook quantization. X. Zhu, J. Song, Lianli Gao, X. Gu, HT. Shen . IEEE Trans. Image Process., 32:2399 - 2412, 2023. CodeTIP 2023From global to local: Multi-scale out-of-distribution detection. J. Zhang, Lianli Gao, B. Hao, H. Huang, J. Song, and H. Shen. IEEE Trans. Image Process., 32:6115–6128, 2023. CodeTNNLS 2023Overcoming Data Deficiency for Multi-Person Pose Estimation. Y. Dai, X. Wang, Lianli Gao, J. Song, F. Zheng, HT. Shen. IEEE Trans. Neural Networks Learn. Syst., 35(8):10857 - 10868, 2023. CodeTMM 2023Resparser: Fully convolutional multiple human parsing with representative sets. Y Dai, X Chen, X Wang, M Pang, Lianli Gao, HT Shen. IEEE Trans. Neural Networks Learn. Syst., 26(5), 1384 - 1394, 2023. CodeTMM 2023Memory-based augmentation network for video captioning. S. Jing, H. Zhang, P. Zeng, Lianli Gao, J. Song, HT. Shen. IEEE Trans. Multim., 26:2367 - 2379, 2023. CodeTMM 2023DMH-CL: Dynamic Model Hardness Based Curriculum Learning for Complex Pose Estimation. Y. Dai, B. Chen, Lianli Gao, J. Song, HT. Shen. IEEE Trans. Multim., 26:2367 - 2379, 2023. CodeTMM 2023Utilizing greedy nature for multimodal conditional image synthesis in transformers. S. Su, J. Zhu, Lianli Gao, J. Song. IEEE Trans. Multim., 26:2354 - 2366, 2023. CodeTCSVT 2023Allowing Supervision in Unsupervised Deformable-Instances Image-to-Image Translation. Y. Liu, S. Su, J. Zhu, F. Zheng, Lianli Gao, J. Song. IEEE Trans. Circuits Syst. Video Technol., 34(3):1743 - 1756, 2023. CodeTCSVT 2023SPT: Spatial pyramid transformer for image captioning. H. Zhang, P. Zeng, Lianli Gao, X. Lyu, J. Song, HT. Shen. IEEE Trans. Circuits Syst. Video Technol., 34(6):4829 - 4842, 2023. CodeTCSVT 2023Complementarity-aware space learning for video-text retrieval. J. Zhu, P. Zeng, Lianli Gao, G. Li, D. Liao, J Song. IEEE Trans. Circuits Syst. Video Technol., 33(8), 4362-4374, 2023. CodeTIP 2022Hierarchical representation network with auxiliary tasks for video captioning and video question answering. Lianli Gao, Y. Lei, P. Zeng, J. Song, M. Wang, and H. T. Shen. IEEE Trans. Image Process., 31:202–215, 2022. CodeTIP 2022Video question answering with prior knowledge and object-sensitive learning. P. Zeng, H. Zhang, Lianli Gao, J. Song, and H. T. Shen. IEEE Trans. Image Process., 31:5936–5948, 2022. CodeECCV 2022State-aware compositional learning toward unbiased training for scene graph generation. T. He, Lianli Gao, J. Song, and Y. Li. IEEE Trans. Image Process., 32:43–56, 2023. CodeCVPR 2022Practical evaluation of adversarial robustness via adaptive auto attack. Y. Liu, Y. Cheng, Lianli Gao, X. Liu, Q. Zhang, and J. Song. IEEE/CVF Conference on Computer Vision and PatternRecognition, CVPR, pages 15084–15093, 2022. CodeCVPR 2022Unified multivariate gaussian mixture for efficient neural image compression. X. Zhu, J. Song, Lianli Gao, F. Zheng, and H. T. Shen. IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, pages 17591–17600, 2022. CodeCVPR 2022Fine-grained predicates learning for scene graph generation. X. Lyu, Lianli Gao, Y. Guo, Z. Zhao, H. Huang, H. T. Shen, and J. Song. IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, pages 19445–19453, 2022. CodeECCV 2022Towards open-vocabulary scene graph generation with prompt-based finetuning. T. He, Lianli Gao, J. Song, and Y. Li. IEEE/CVF International Conference on Computer Vision, ICCV, pages 56–73, 2022. CodeECCV 2022Frequency domain model augmentation for adversarial attack. Long, Q. Zhang, B. Zeng, Lianli Gao, X. Liu, J. Zhang, and J. Song. IEEE/CVF International Conference on Computer Vision, ICCV, pages 549–566, 2022. CodeICLR 2022Beyond imagenet attack: Towards crafting adversarial examples for black-box domains. Q. Zhang, X. Li, Y. Chen, J. Song, Lianli Gao, Y. He, and H. Xue. The Tenth International Conference on Learning Representations, ICLR, 2022. CodeNeurIPS 2022A differentiable semantic metric approximation in probabilistic embedding for cross-modal retrieval. H. Li, J. Song, Lianli Gao, P. Zeng, H. Zhang, and G. Li. Advances in Neural Information Processing Systems, NeurIPS, 2022. CodeNeurIPS 2022Natural color fool: Towards boosting black-box unrestricted attacks. S. Yuan, Q. Zhang, Lianli Gao, Y. Cheng, and J. Song. Advances in Neural Information Processing Systems, NeurIPS, 2022. CodeNeurIPS 2022A lower bound of hash codes’ performance. X. Zhu, J. Song, Y. Lei, Lianli Gao, and H. Shen. Advances in Neural Information Processing Systems, NeurIPS, 2022. CodeTPAMI 2020Hierarchical lstms with adaptive attention for visual captioning. Lianli Gao, X. Li, J. Song, and H. T. Shen. IEEE Trans. Pattern Anal. Mach. Intell., 42(5):1112–1131, 2020. Code
🎖 Honors and Services
- Research Honors:
- 2025 “Shi Qingyun” Women Scientists Award of China Society of Image and Graphics 2025.
- 2024 Best paper Candidate of ICME 2024.
- 2023, 2024 Rising Star of Science Award.
- 2023, 2020, 2018 UESTC Research Excellence Award.
- 2023, 2018 UESTC Excellent Faculty Award for Teaching Excellence.
- 2023 Chinese Young Female Scholars in Artificial Intelligence.
- 2021 Sichuan Provincial Academic/Technical Leader (Reserve Candidate).
- 2020 IEEE Technical Community on Multimedia Computing Rising Star Award.
- 2019 Alibaba DAMO Academy Young Fellow Award.
- 2017 Australasian Database Conference Best Student Paper Award.
- Grand Challenges:
- ECCV 2022: DeeperAction Challenge 3rd place award on Track 4 Kinetics-TPS Challenge on Part-level Action Parsing.
- CVPR 2021: Security AI Challenger Phrase VI Track 1st Place award in White-box Adversarial Attacks on ML Defense Models.
- ICCV 2021: DeeperAction Challenge 3rd Place award on Track 3 Kinetics-TPS Challenge on Part-level Action Parsing.
- OPPO 2021: Security Challenge 2nd Place award.
- ICCV 2019: COCO DensePose Task Challenge 2nd place award.
- Academic Services:
- To date: NeurIPS Area Chair, CVPR Area Chair, ICCV Area Chair, ECCV Area Chair, ACM MM Area Chair, AAAI Area Chair, WACV Area Chair, BMVC Area Chair, etc.
-
- 2027:Senior Program Committee of AAAI 2027, WACV Area Chair
- 2026: Area Chair of WACV 2026, Senior Program Committee of AAAI 2026, Area Chair of CVPR 2026, Area Chair of ACM MM, Area Chair of ECCV, Area Chair of NeurIPS, WACV Area Chair.
- 2025: Senior program committee of AAAI 2025, ICME Area Chair, AAAI Area Chair, CVPR Area Chair, ICCV Area Chair, ACM MM Area Chair.
- 2024: General Chair of Inaugural Young Scientists Salon on Artificial Intelligence.
- 2024: Associate Editor for IEEE Transactions on Multimedia 2024!
- 2024: ECCV Area Chair, WACV Area Chair, program committee of the IJCAI 24 track on AI and Social Good.
- 2023: WACV Area Chair
- 2022: AAAI SPC, WACV Area Chair
- 2021: ACM MM Session Chair, ACM MM Workshop Co-chair
- 2019: IJCAI Session Chair, Guest Editor of Journal of Visual Communication and Image Representation, etc.
- 2018-Now: Reviewers of IEEE TPAMI, TIP, TMM, TNNLS, TOC; IJCV; CVPR, ECCV, ICCV, AAAI, IJCAI, NeurIPS, ICML, MM, IJCAI and etc.
🙋 Supervisions
- Current Ph.D students:
- Yijun Xue, Yinghang Duan, Jiawei Zhou (Enrolled in Jun. 2025)
- Junhong Zhu, Youguang Xing, Hao Wu (Enrolled in Jun. 2024)
- Kaipeng Fang, Xiao Cai, Beitao Chen, Shengming Yuan (Enrolled in Jun. 2023)
- Xu Luo, Haonan Zhang, Chen Chen (Enrolled in Jun. 2022)
- Hao Ni, Sitong su (Enrolled in Jun. 2021)
- Ji Zhang, Xinyu Lyu, and Juncheng Zhu (Enrolled in Jun. 2020)
- Former Ph.D students:
-
Tao He (Co-supervisor Monash University Jun.2018 - Nov. 2022)
Thesis: Towards Unbiased Scene Graph Generation: Techniques and Applications.
-
Xuanhang Wang (Jun. 2019 - Jul. 2023)
Thesis: Visual semantic understanding based visual dialogue.
-
Pengpeng Zeng (Jun. 2019 - Jul. 2023)
Thesis: Research on Synergizing Vision and Text for Semantic Consistency Method.
-
Xiangpeng Li (Jun.2018 - Jul. 2022)
Thesis: Research on Visual Reasoning algorithm that integrates natural language analysis.
-
Yuyu Guo (Jun. 2018 - Jul. 2022)
Thesis: Visual Relationship Generation Based on Scene Understanding.
-
- Current and former M.Sc. students:
- Hilali Sara Rita,Ke Liu, Mengqi Li, Shihan Wu, Fuwei Liu, and Lu Zhu (Enrolled in Sep. 2022)
- Jiaqi Guo, Qisheng Chen, Youheng Sun, Yixin Qin, and Han Wang (Enrolled in Sep. 2022)
- Durasic Aleksandra, Fuchun Wang, and Hao Wu (Enrolled in Sep. 2021)
- Xiaoya Chen, Kai Xing, Jiahui Li, and Wenxue Shen (Graduated Jun. 2023)
- Qike Zhao, Yaya Cheng, and Haoyu Wang (Graduated Jun. 2022)
- Zhilong Zhou, Qian Ye, Hao He, and Ruiming Lang (Graduated Jun. 2021)
- Qingsong Zhang, Liyang Zhang, and Ziming Fang (Graduated Jun. 2020)
- Yuyu Guo (Graduated Jun. 2019)
- Liangfu Cao (Graduated Jun. 2018)
- Chuanshu Long (Graduated Jun. 2017)
💻 Research Grants
Some selective Research Grants:
- 2024.01 - 2027.12, Key Program of National Natural Science Foundation of China: “Trusted Big Cross-Meida Data Analysis and Key Technologies”, Lead PI
- 2022.01 - 2024.12, Distinguished Young Scholars of the National Natural Science Foundation of China: “Visual Cognition by Integrating Natural Language”, Lead PI.
- 2019.01 - 2022.12, General Program of National Natural Science Foundation of China: “Deep Visual Understanding by Fusing Natural Language Processing”, Lead PI.
- 2016.01 - 2018.12, Young Scientists Fund of the National Natural Science Foundation of China: “Deep Learning and Event Driven based Video Mashup”, Lead PI.